今天我們來帶大家實作一下如何在BigQuery裡使用Dataflow SQL的語法,即時讀取Pub/Sub串流資料,並同步關聯BigQuery中的某一既有表格來處理資料,並將關聯過後的資料匯出至BigQuery的另一個資料表中。
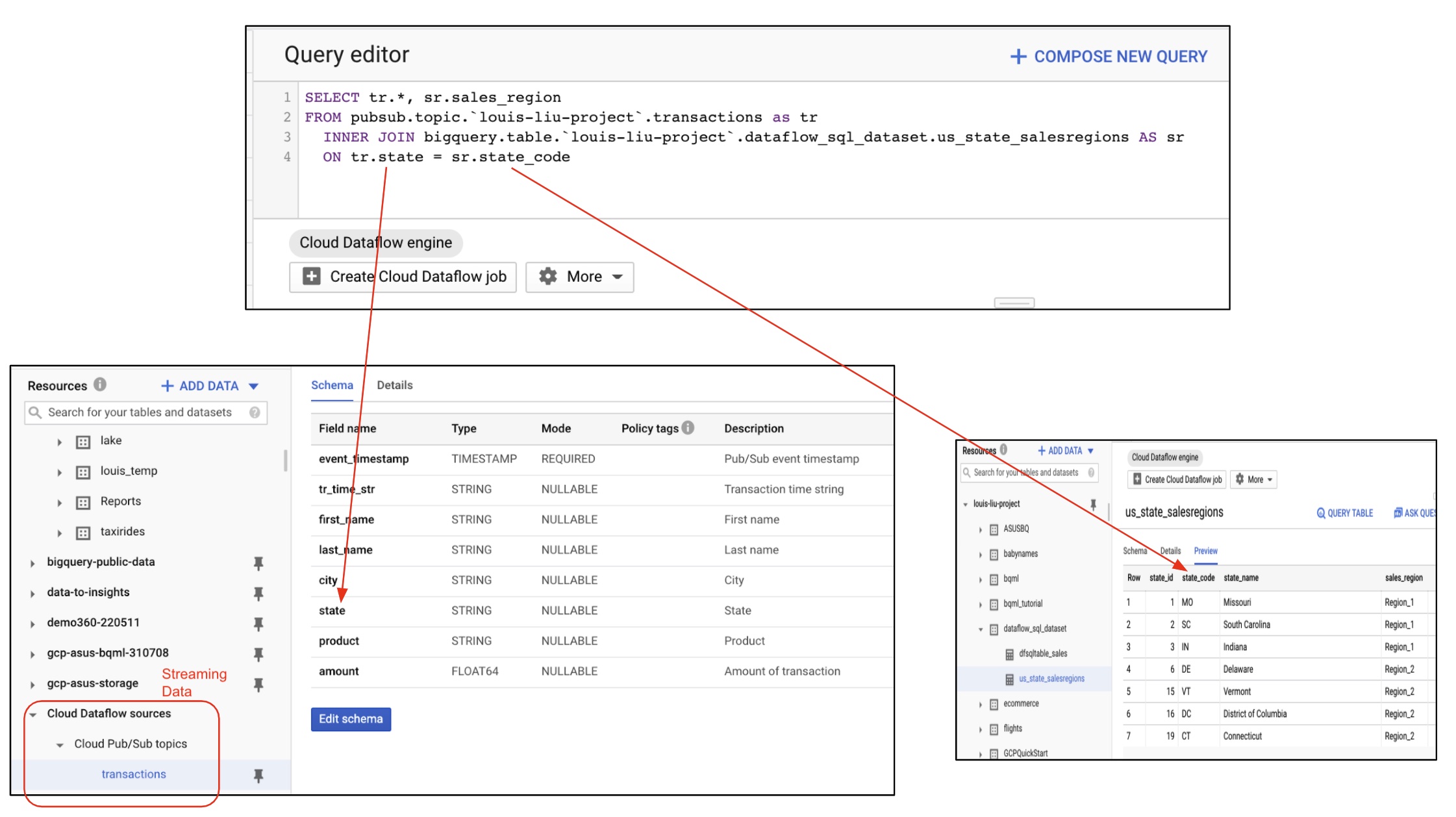
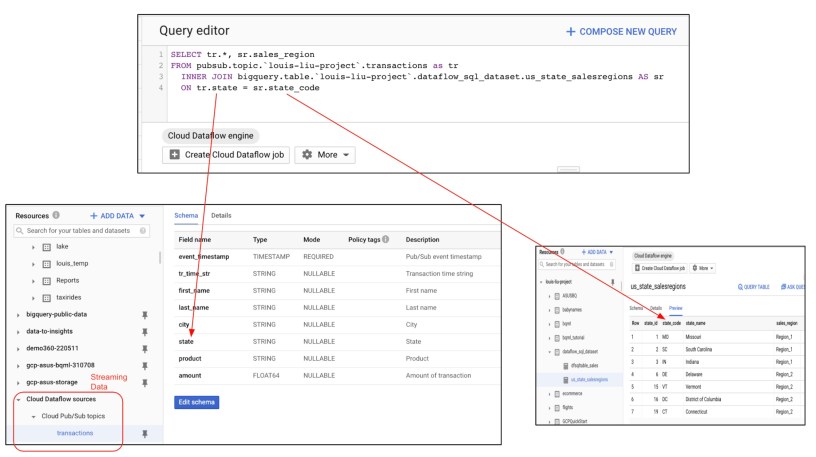
BigQuery以Dataflow SQL語法讀取Pub/Sub串流資料並關聯既有表格以產生新表格
上圖的左邊為BigQuery需要即時讀取的串流資料來源資料表,內容包含客戶名稱、客戶購買的產品和購買時間、價格、城市、州別等欄位。此資料表的內容我們會以Python程式將模擬的客戶相關購買資訊即時發佈到Pub/Sub的“transactions”主題;另外BigQery需以設定外部資料集為Pub/Sub的方式來獲取客戶購買資料,以供Dataflow SQL可以做資料的即時處理。
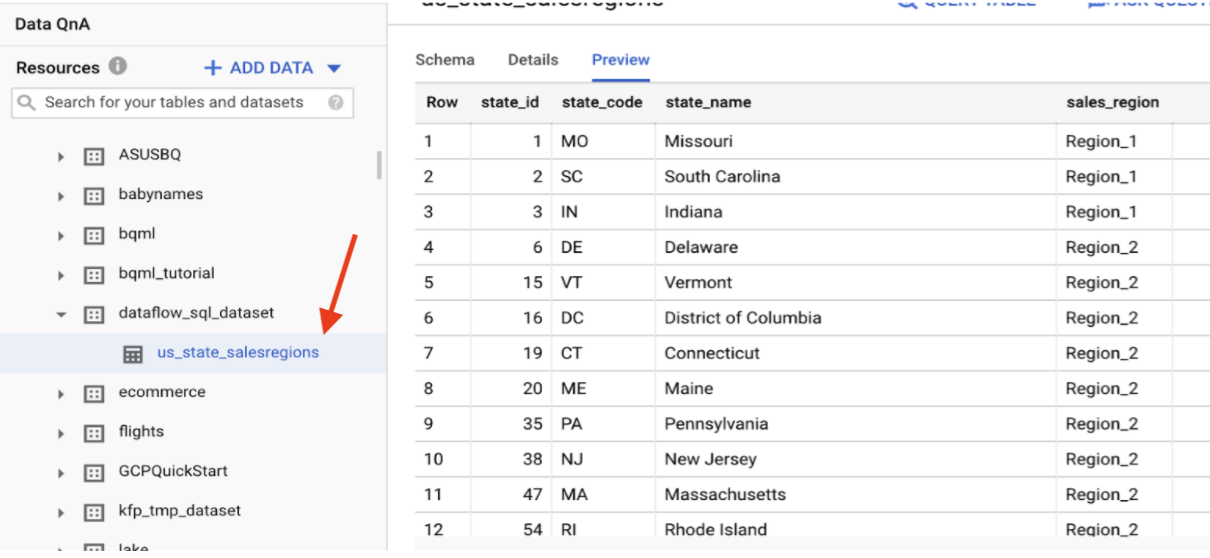
上圖的右邊為事先已存在BigQuery的銷售靜態資料表,內容為美國各州的代號、州名和它們所對應的公司銷售區域。
整個流程為:
- 變更BigQuery處理SQL方式
- 建立Dataflow需要處理的資料表來源
- 用腳本隨機產生客戶購買資料
- 在BigQuery中撰寫Dataflow SQL語法以讀取和處理資料
- 查看匯出資料
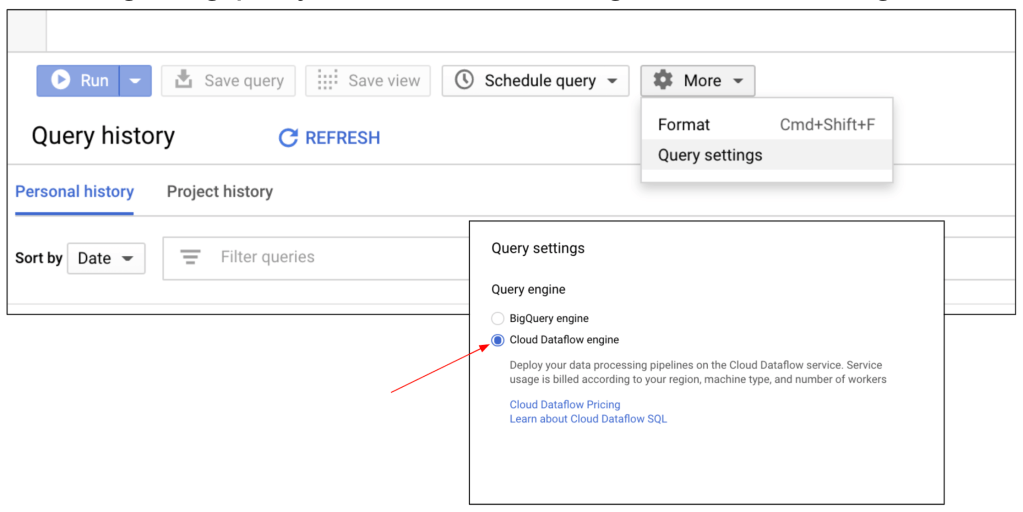
設定BigQuery預設之標準SQL語法變更為Dataflow的處理方式
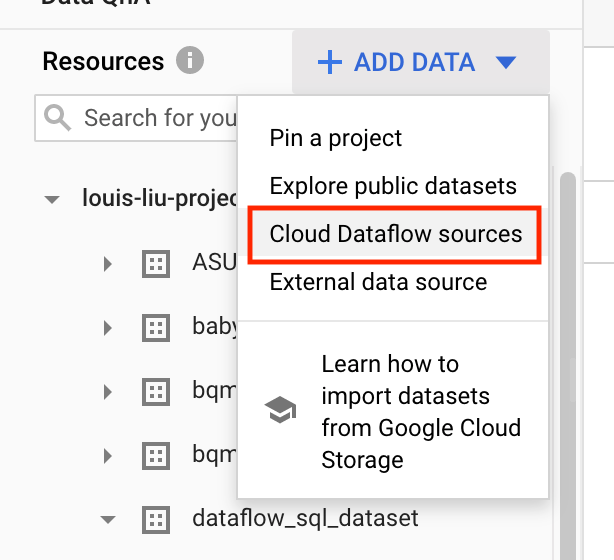
建立串流資料源
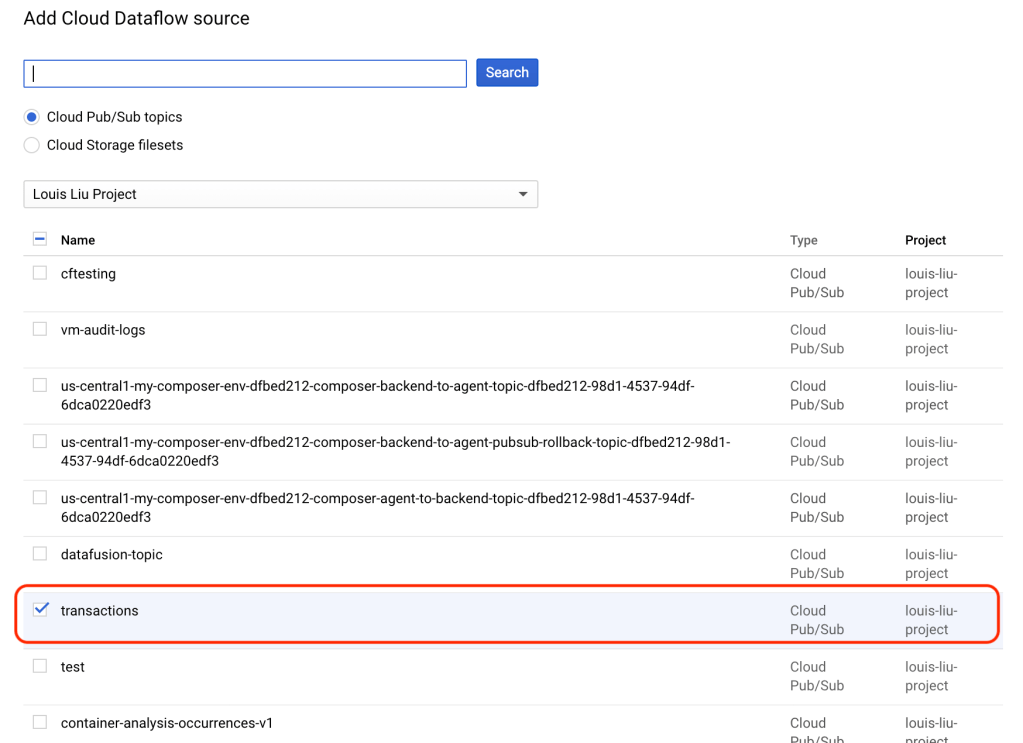
首先建立一個名為”transactions”的Pub/Sub主題:

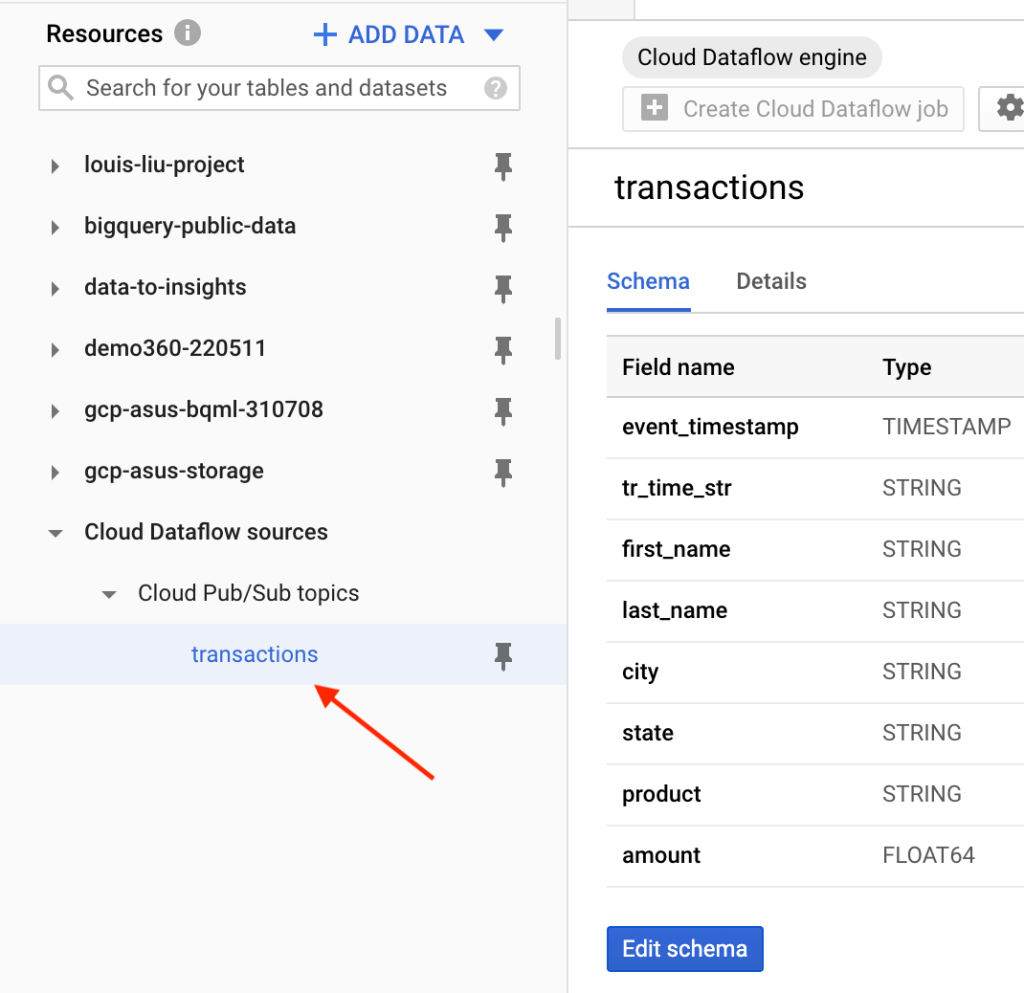
然後在BigQuery新增以上所建立的Pub/Sub主題資源:(需要定義相關欄位資訊)
建立靜態銷售資料表
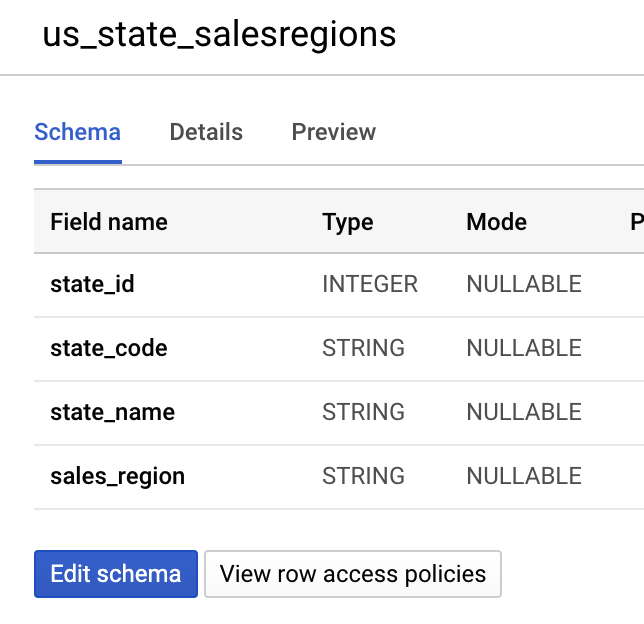
在BigQuery建立靜態銷售資料表”us_state_salesregions”:
執行python腳本動態隨機產生客戶購買產品資訊,這些資訊會被發佈到之前已建立的Pub/Sub的”transactions”主題中:
在Query editor中加入SQL查詢語法,在此我們比對來自於串流資料中的客戶購買資料中的“state”欄位值如果和事先存在的”transactions”資料表中的”state_code”相同的話,就把“sales_region”欄位的內容加進串流資料,並將結果存於指定的資料表。
(執行Dataflow後,Google Cloud會在後台建立可以執行Apache Beam的Worker Node)

將結果存到指定的”dfsqltable_sales”表格中
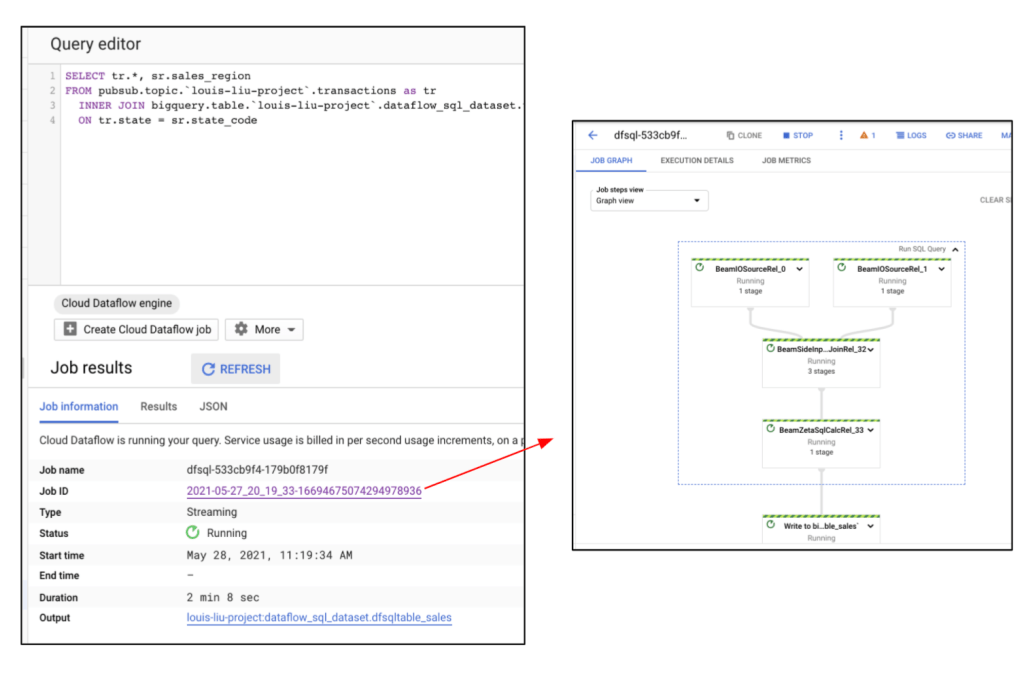
Dataflow Job執行後,可在BigQuery GUI中查看Dataflow資料處理流程和狀況
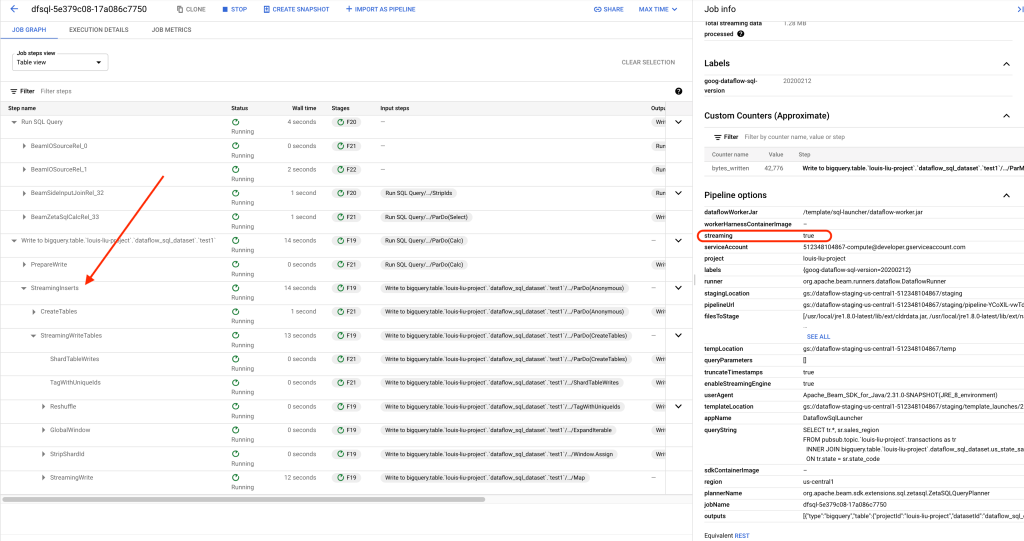
Dataflow GUI streaming insert
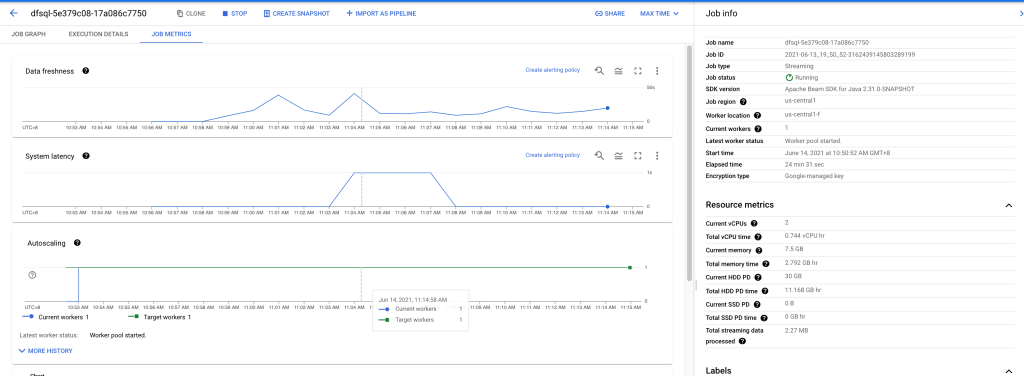
Dataflow job會於後台自動根據工作負載做Autoscaling Worker Nodes的動作
Google Cloud Dataflow會將結果存放在指定的Table內:
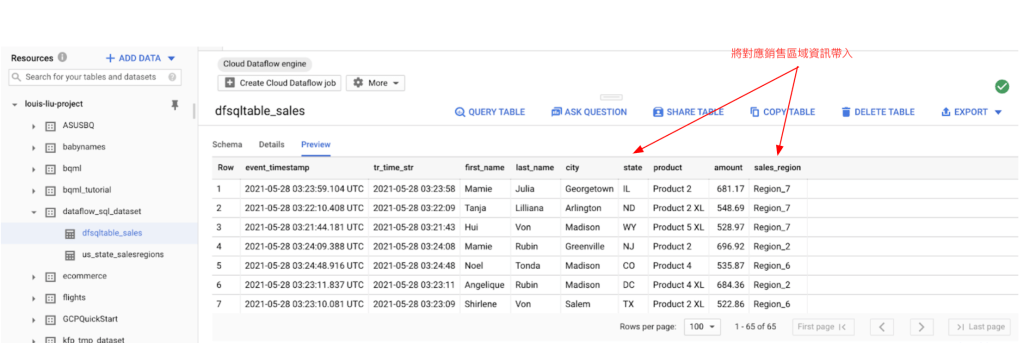
產生的資料多了一個對應的欄位
我們也可在BigQuery的Job history頁籤中查看Dataflow過去執行的歷史狀況!
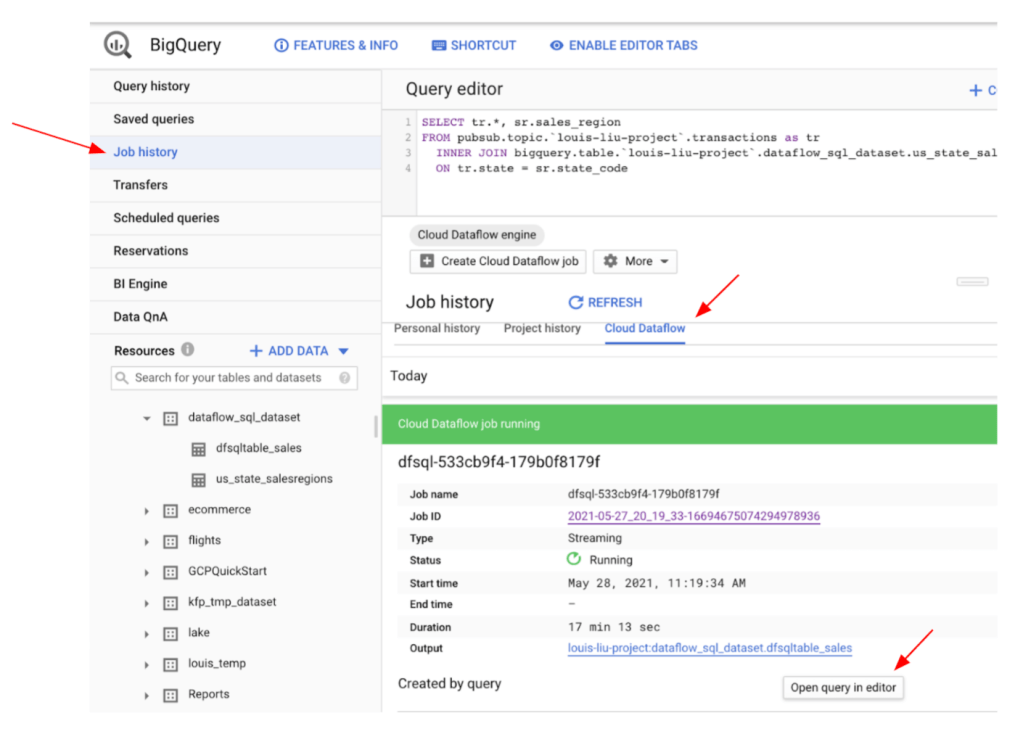
Dataflow歷史執行記錄
結論
Cloud Dataflow 是一個Serverless平台,可以執行Batch和Sreaming的資料,它是基於Apache Beam SDK的實作,屬於Google Cloud眾多服務下的ETL工具之一,常用於數據管道中的資料轉化、變形、清整變成另一種資料,例如清除重複、空值、需求不符的資料、讀取並結合不同資料來源,合併做計算和統計等等;我們除了可以利用Dataflow中內建的connector(template)去連接不同的資料來源之外,由於Dataflow 是使用開源的函式庫 Apache Beam,所以我們在建構資料處理管道的時候,也可以使用 Apache Beam APIs。
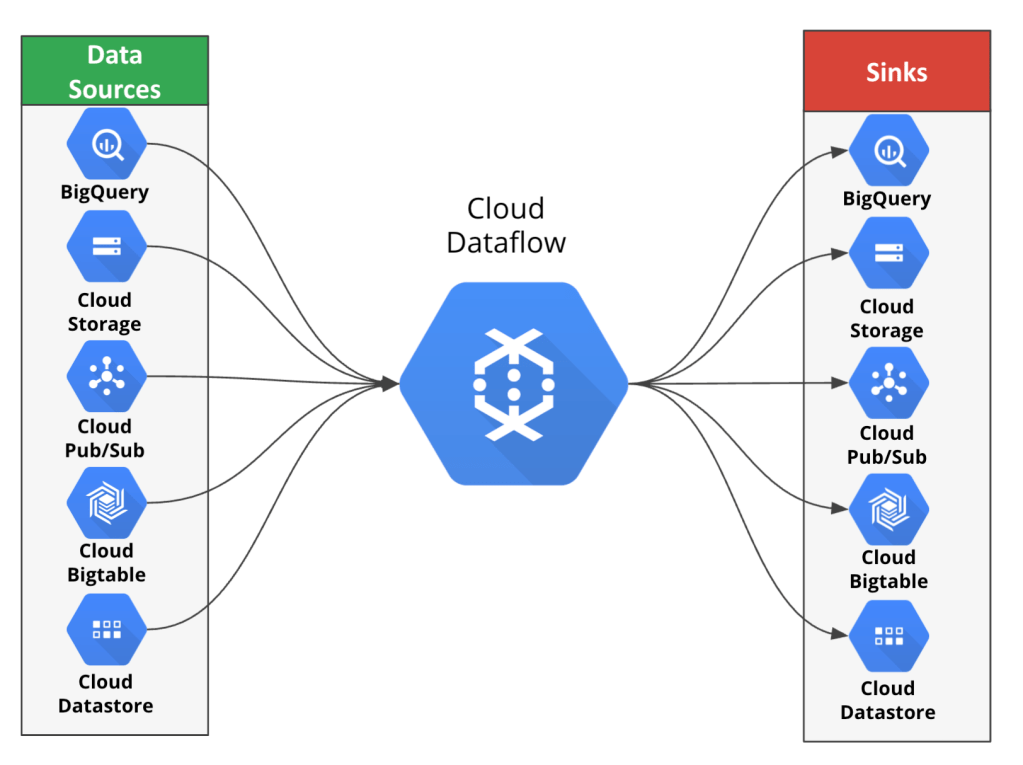
Data Sources and Sinks for Dataflow
備註
此篇實作參考Google Dataflow tutorials: Joining streaming data with Dataflow SQL
