
For those who wish to send data from MSSQL to BigQuery without coding for the pipeline design, you can leverage Google’s Cloud Data Fusion to accomplish this goal, this blog will show you how to create and deploy a pipeline that continuously replicates changed data from a Microsoft SQL Server database to a BigQuery table.
The whole configurations may involve the following steps:
- Set up MSSQL Server database to enable replication
- Create and run a Cloud Data Fusion Replication job
- View the results in BigQuery
1. Set up MSSQL to enable replication
- prepare the database
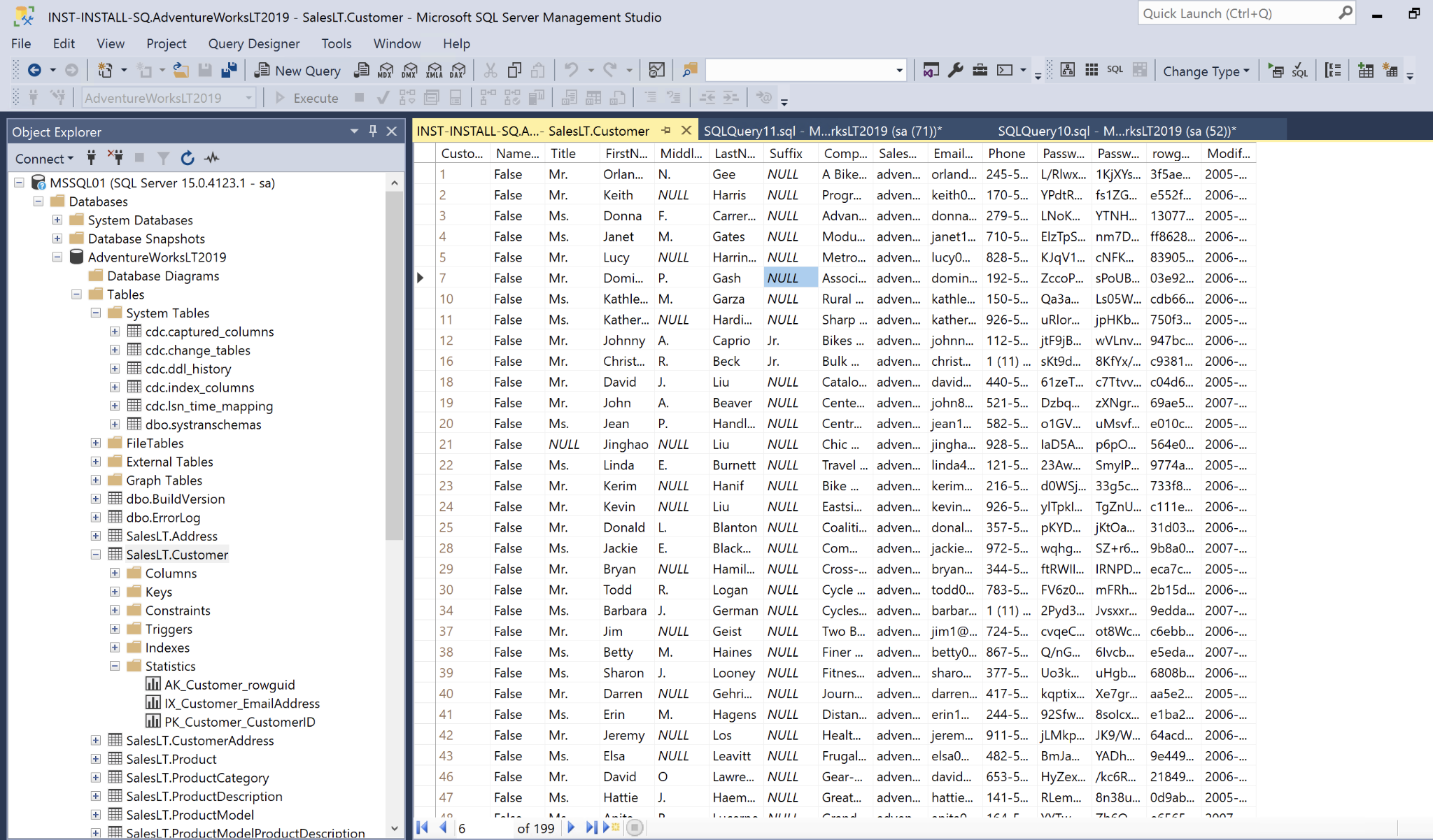
During my testing, I installed DB with sample data from MS, you can refer to this page for the detail setup. The following graph showing that I have AdventureWorksLT2019 DB installed.
- Enable Change Data Capture (CDC) replication
You can now decide which table you want to enable the realtime replication capability with BigQuery, refer to this page and issue the following sample command to enable the table CDC. Cloud SQL also can let you perform such configuration via MS SSMS or SQL command.
USE AdventureWorksLT2019
GO
EXEC sys.sp_cdc_enable_db
GO
EXEC sys.sp_cdc_enable_table
@source_schema = N’SalesLT’,
@source_name = N’Address’,
@role_name = NULL;
GO
2. Create and run a Data Fusion replication job
- Crate Cloud Data Fusion instance
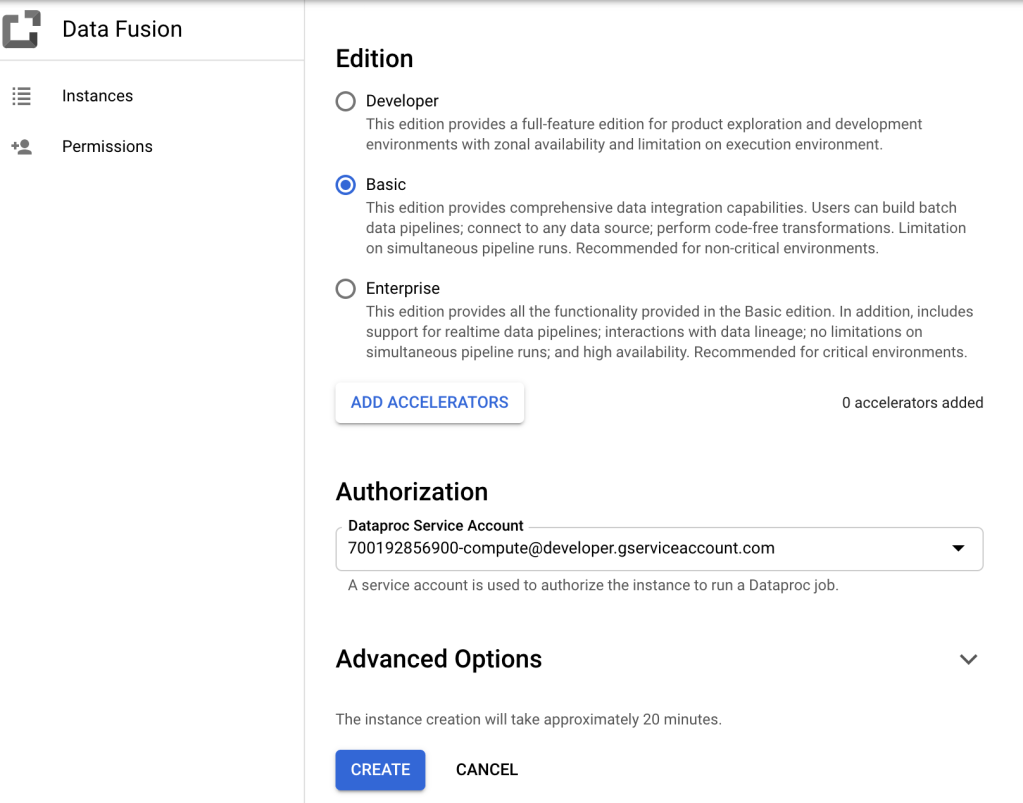
After we have enabled CDC for specific tables, then we want to create CDF (Cloud Data Fusion), just go to GCP console and create CDF, remember to click “ADD ACCELERATORS” button, which will allow you to perform the “Replicate” setup by uploading the JDBC driver to CDF. (if you want to setup the CDF with Private IP, you need to particularly tick the checkbox in the “Advanced Options” during the creation process.
- Configure the CDF
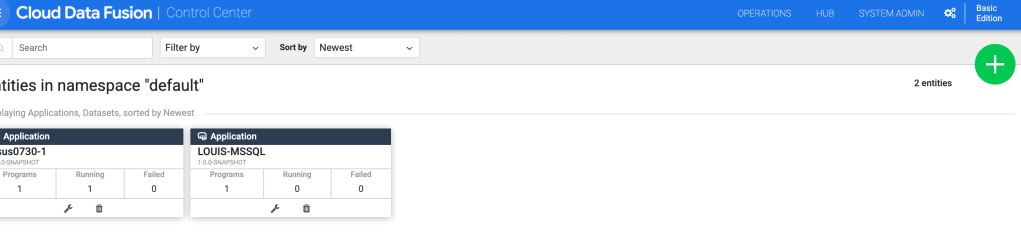
After the CDF instance has been created, we need to upload required driver (download available here) for the replication, go to CDF Control Center and click the green round icon with plus sign on the upper right-hand side to upload driver.
Click the “Driver” tile:
upload your driver, remember to assign the correct classname for that driver. (com.microsoft.sqlserver.jdbc.SQLServerDriver)
- Create the replication job
Go to CDF home page, click the Replication tile:
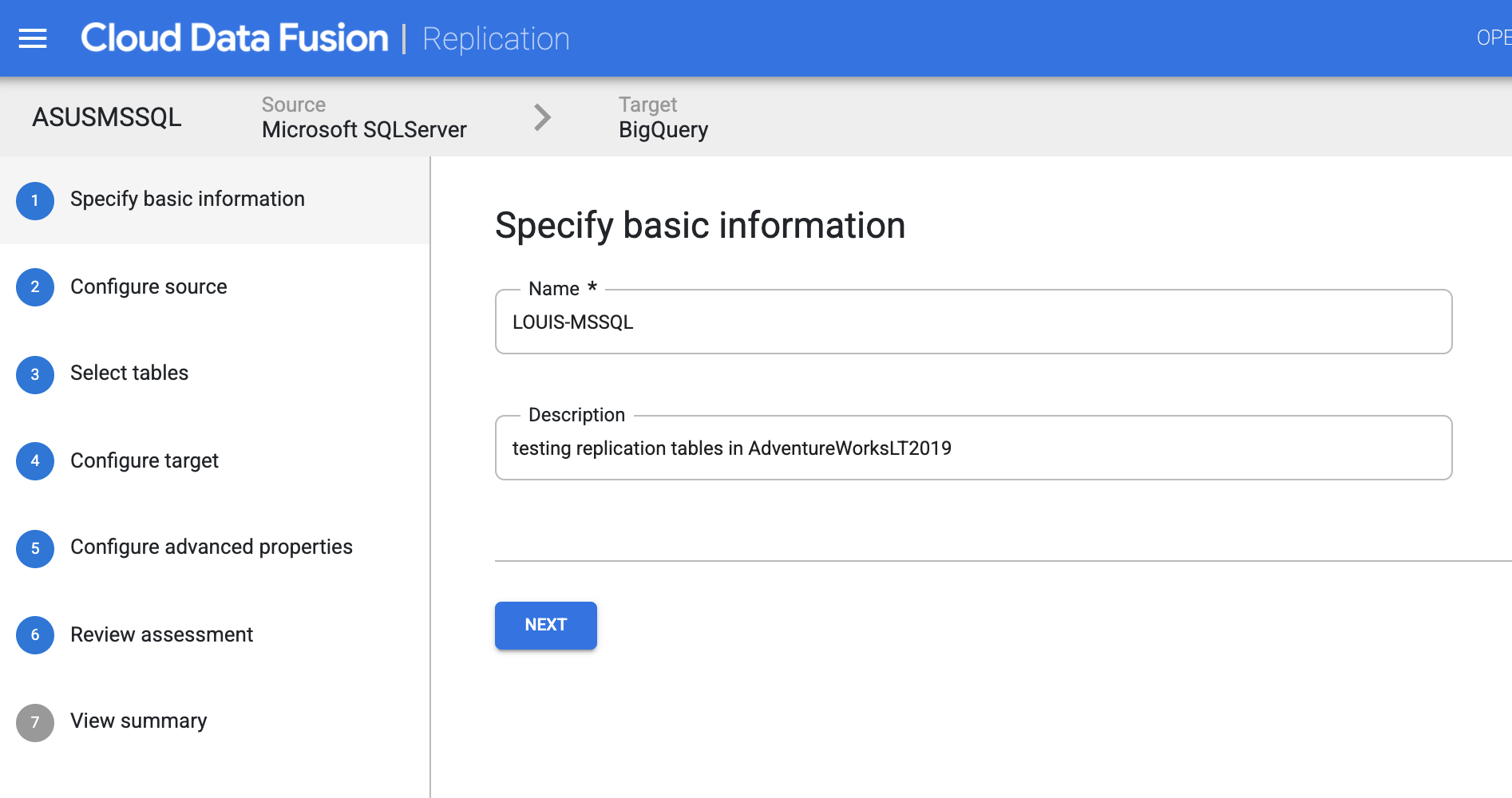
Click the little green icon on the upper-right hand side to create a replication job:

Followings are the screen captured for the whole job creation processes:
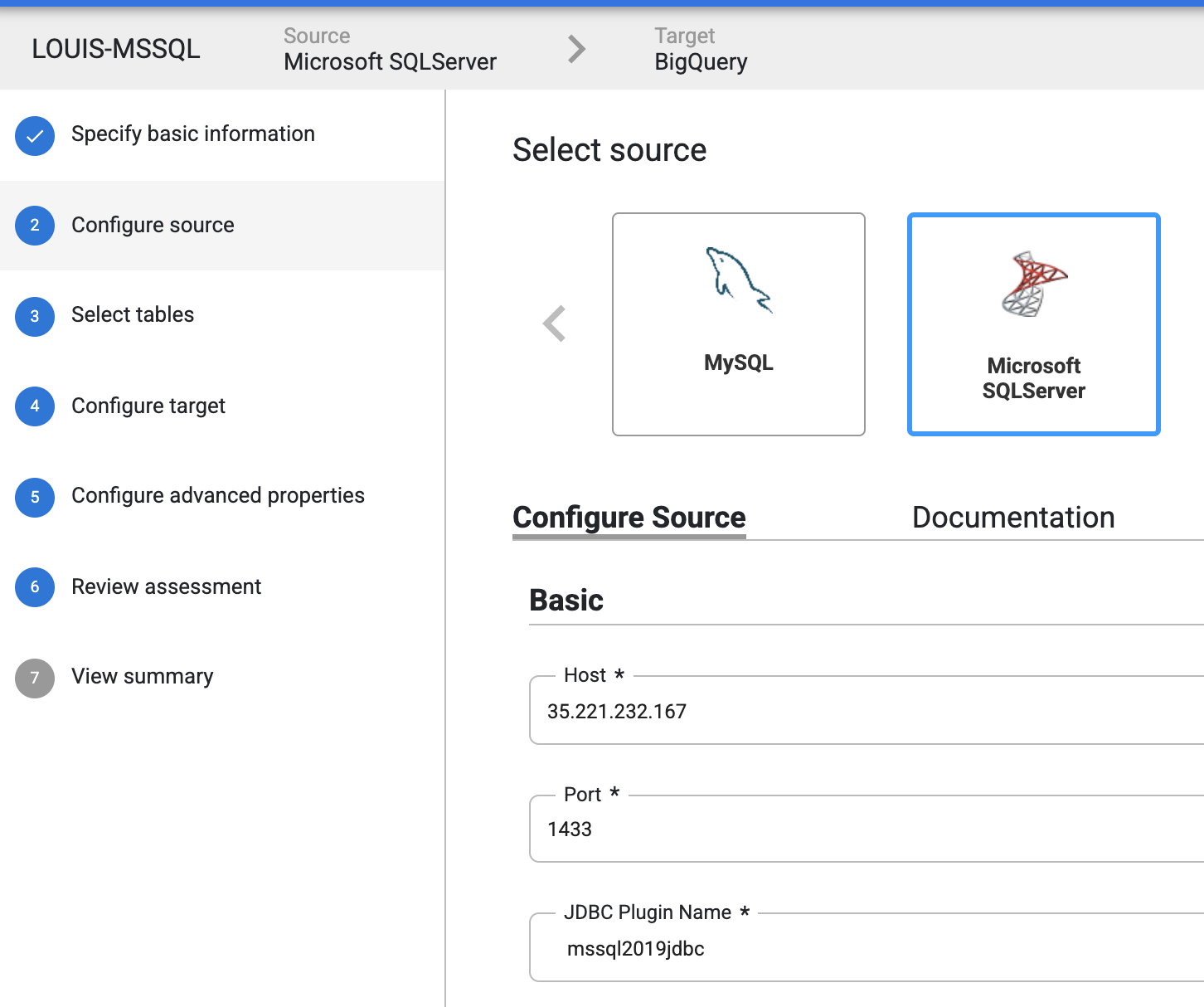
Choose MSSQL source (Cloud SQL also applied), and choose the JDBC we just uploaded earlier:
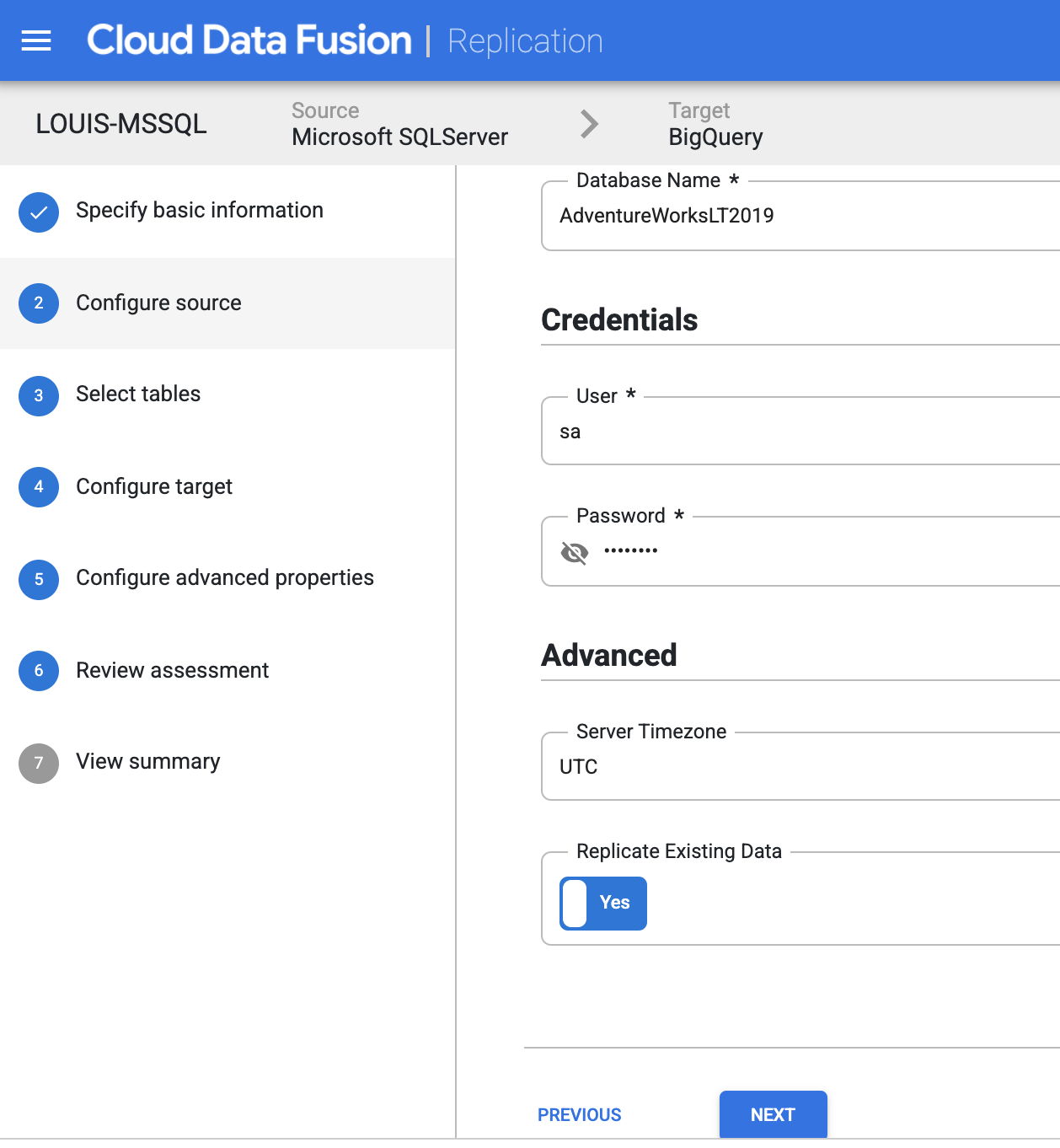
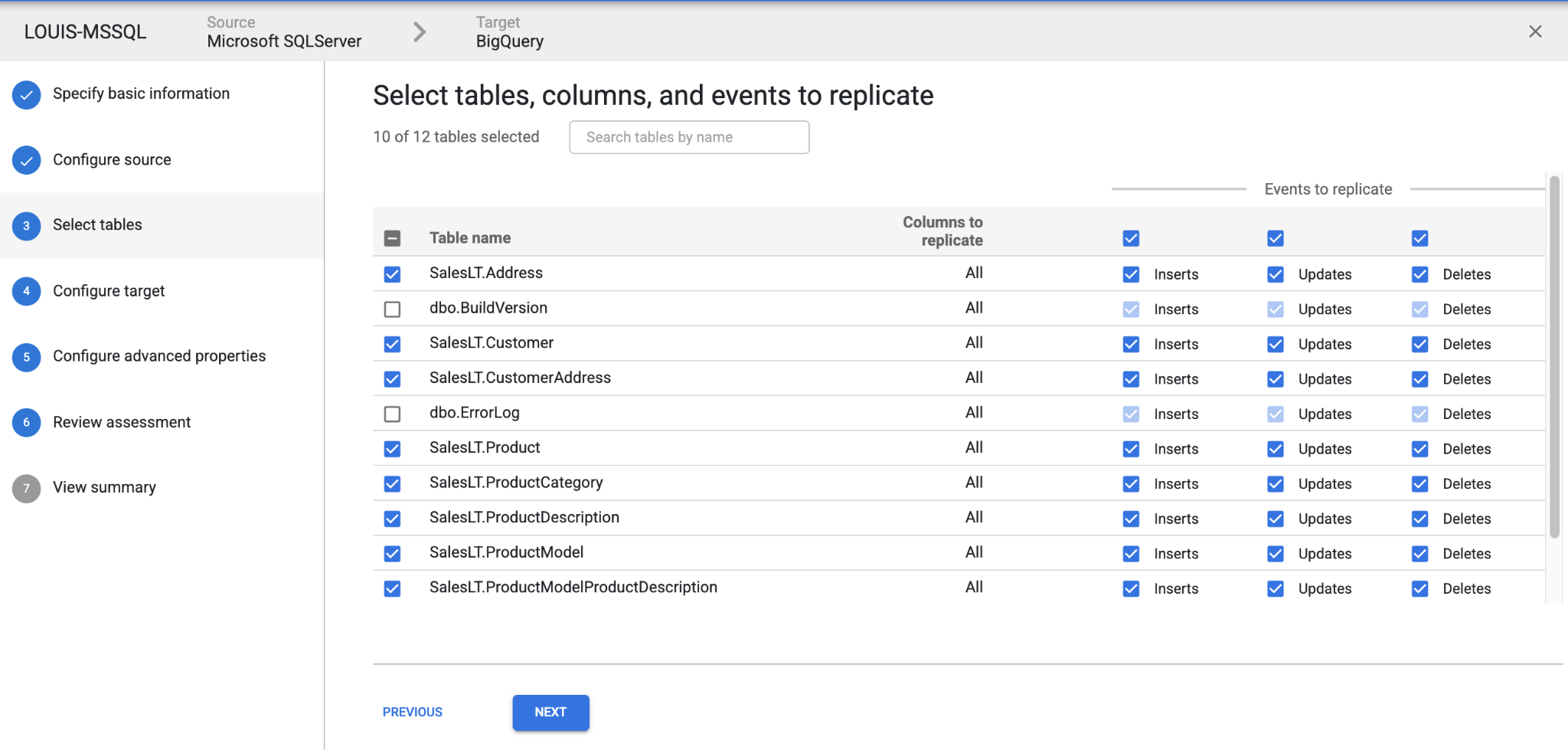
Choose which tables you want to sync with BigQuery:
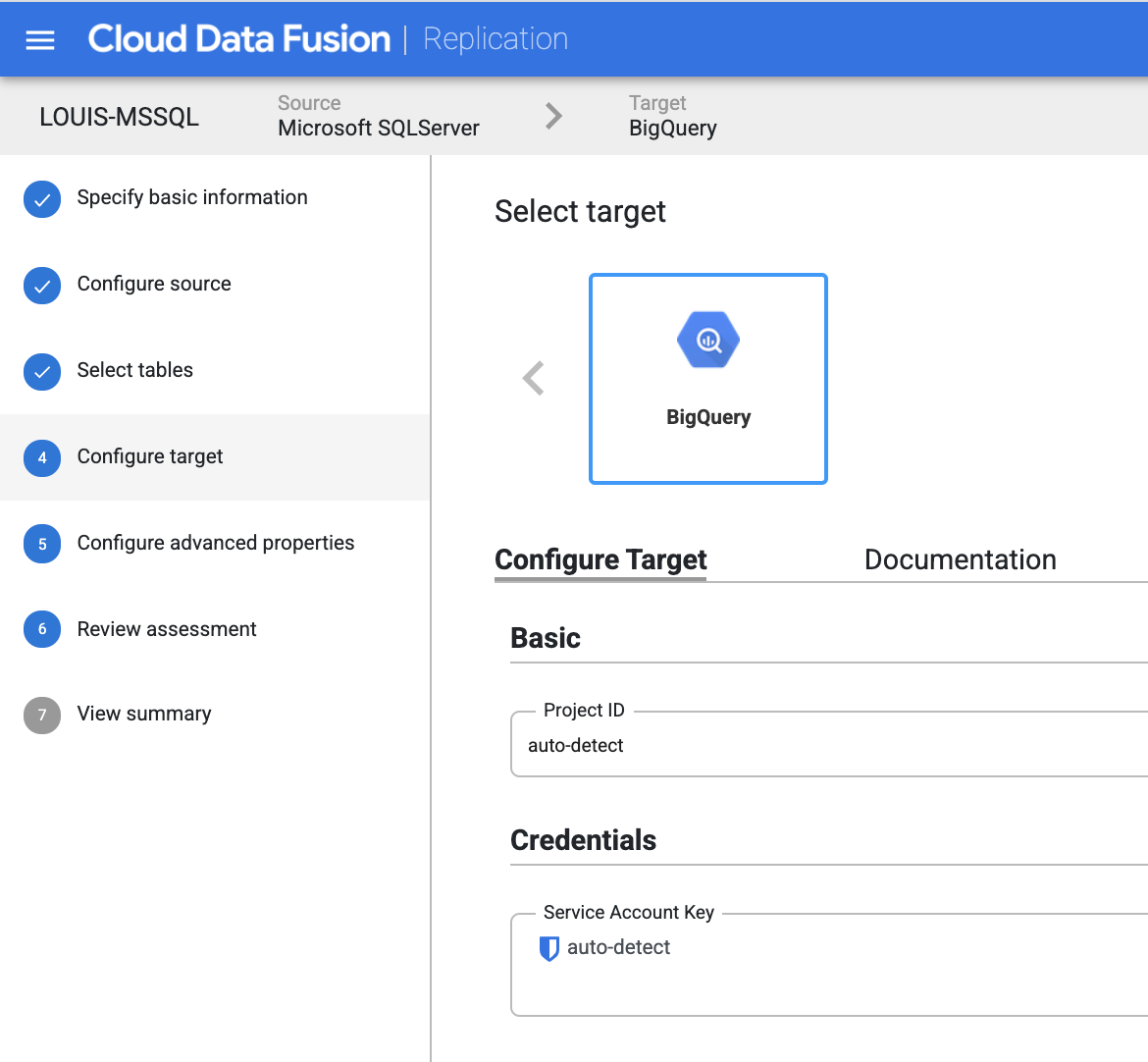
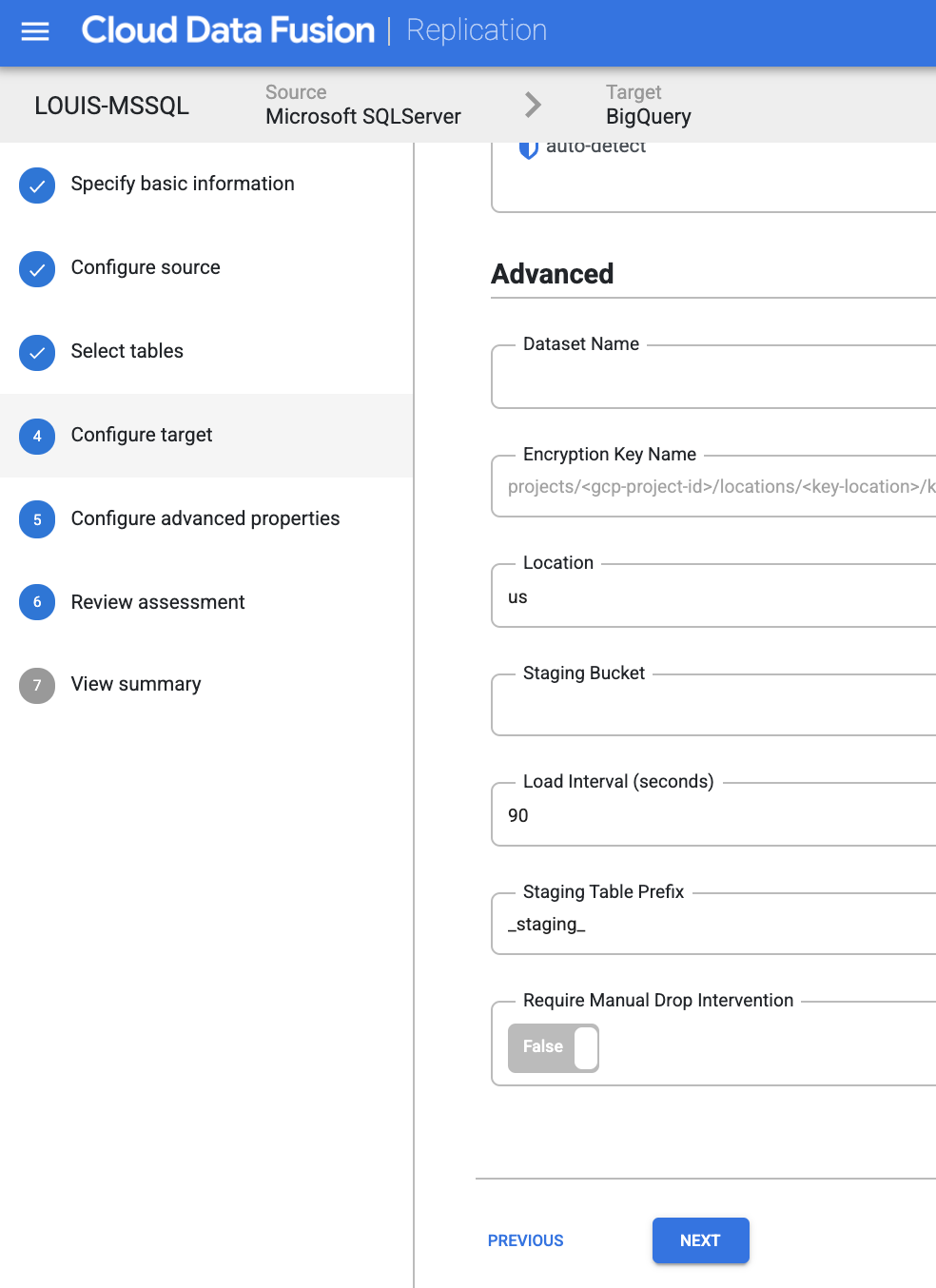
specific the BigQuery target destination, which project, which dataset, etc.,
Specify the dataset name you wish BigQuery to store the synced data:
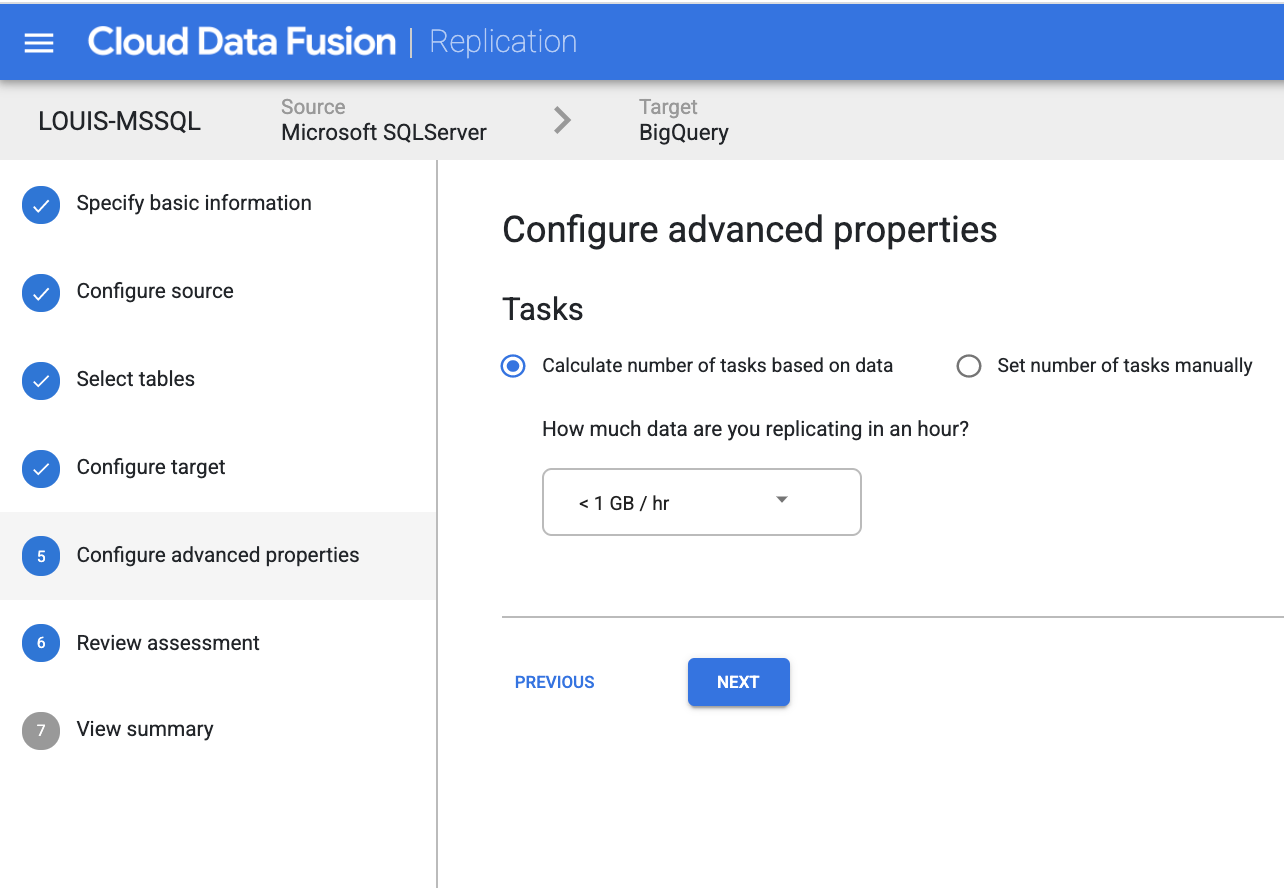
input data change size in an hour:
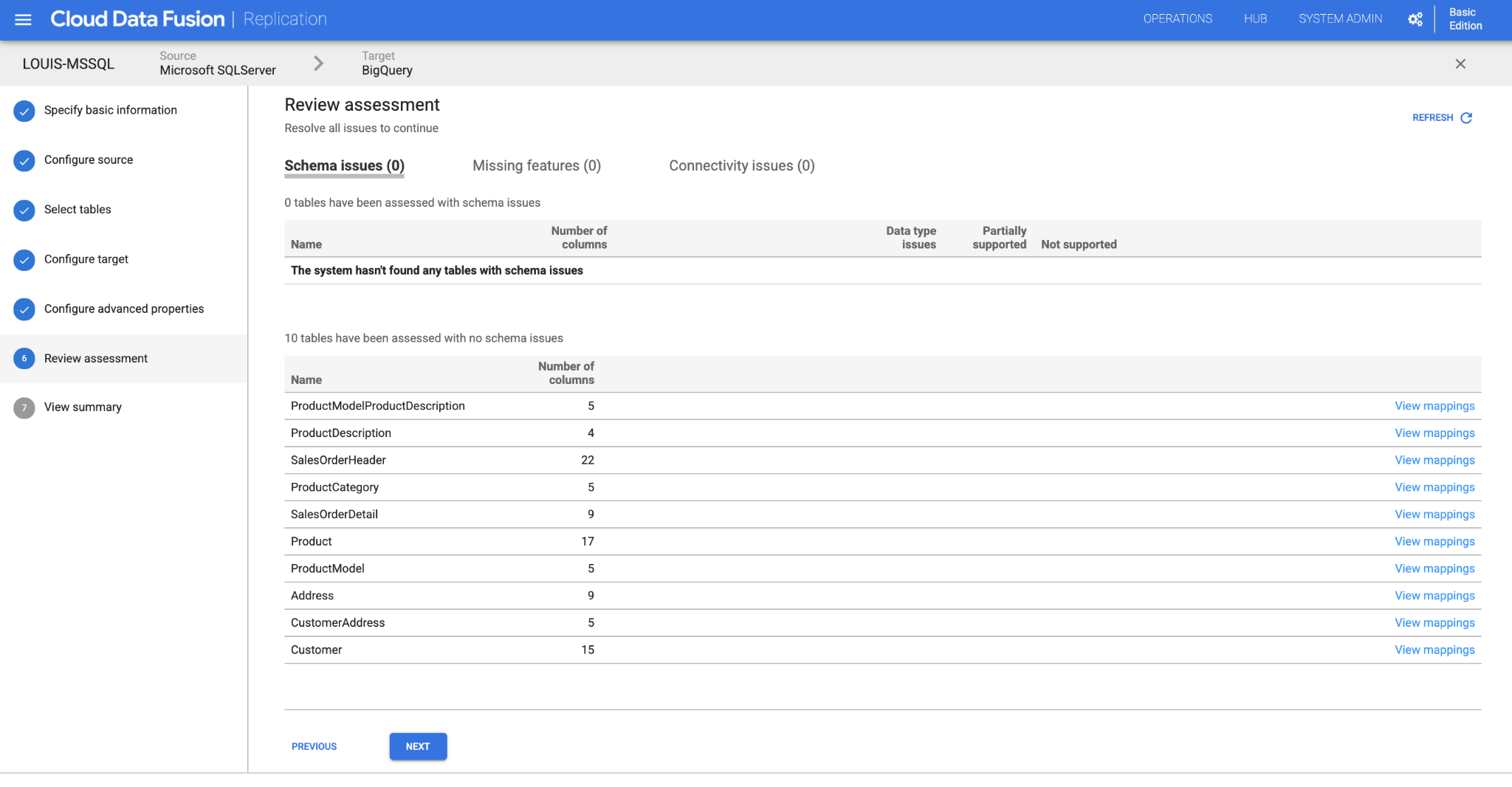
Review the assessment information, CDF will check back these with our source data:
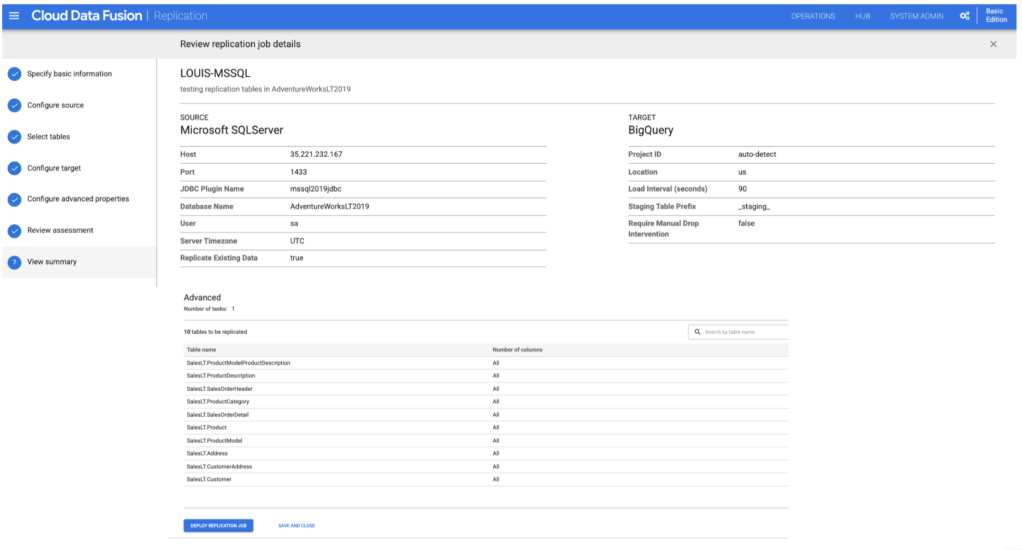
View summary and deploy job:
We can see the replication job’s overview and monitor the status, click the “Start” button to begin the replication.
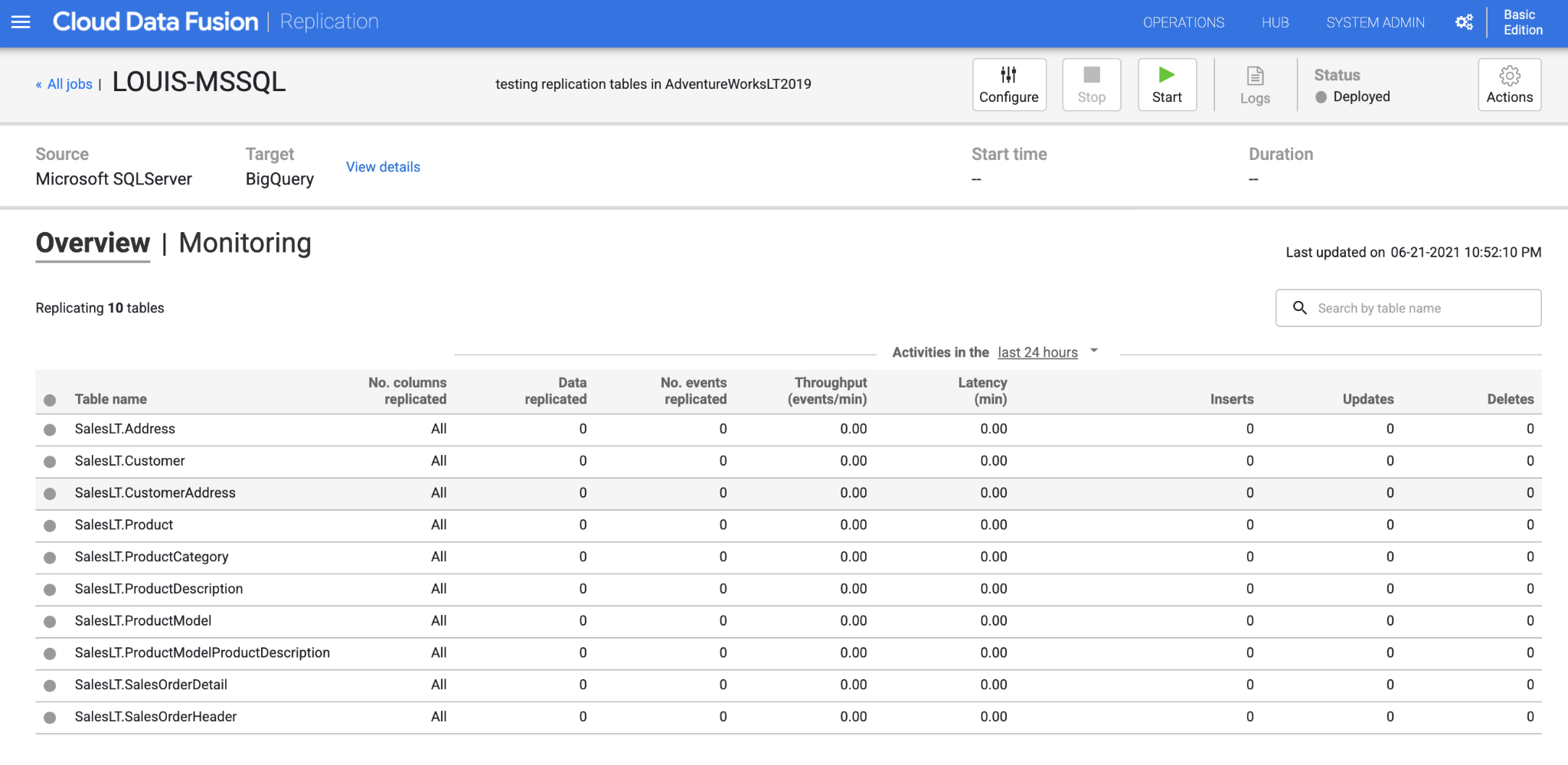
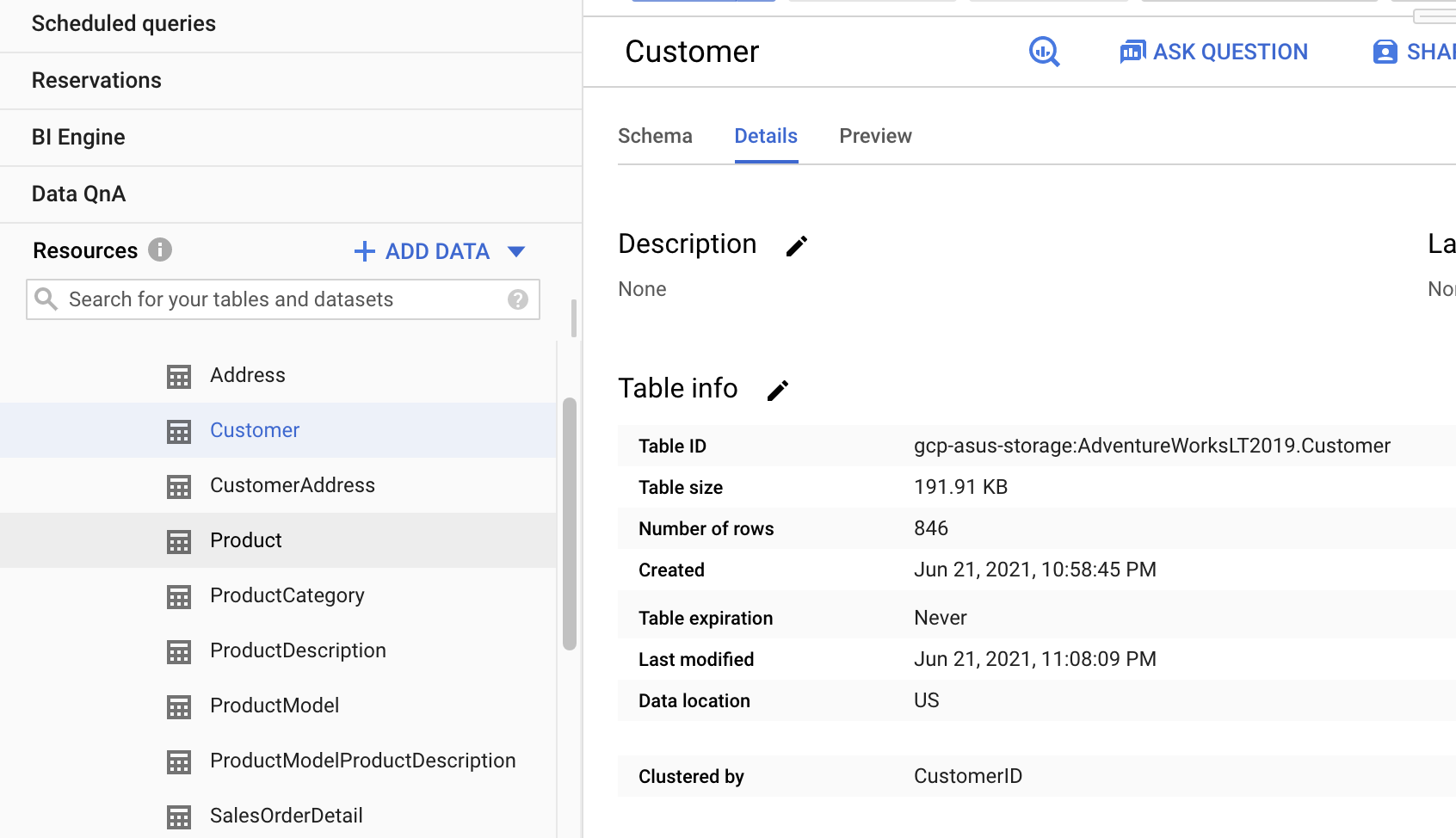
After several minutes, the page will update synced data in BigQuery.
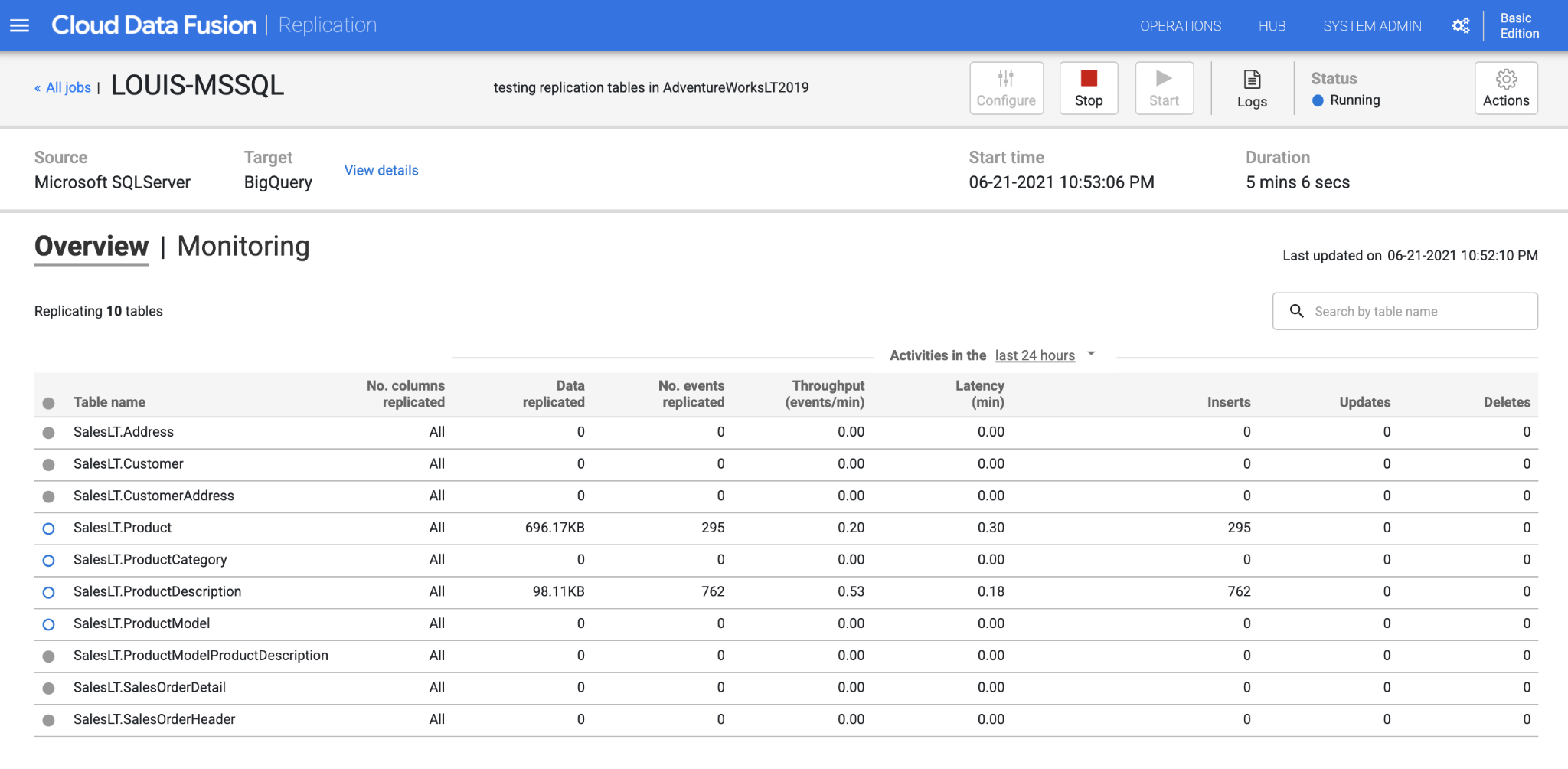
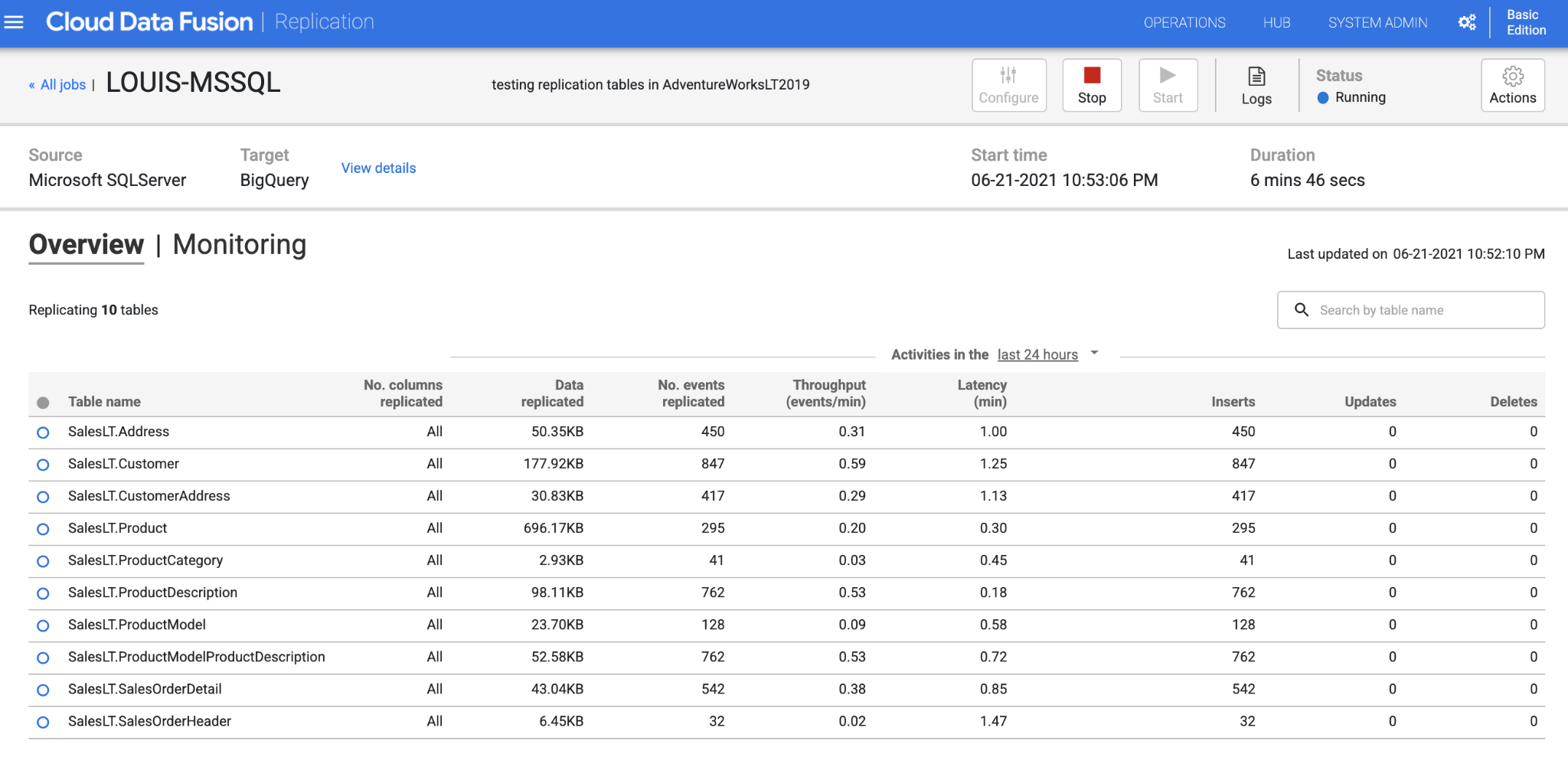
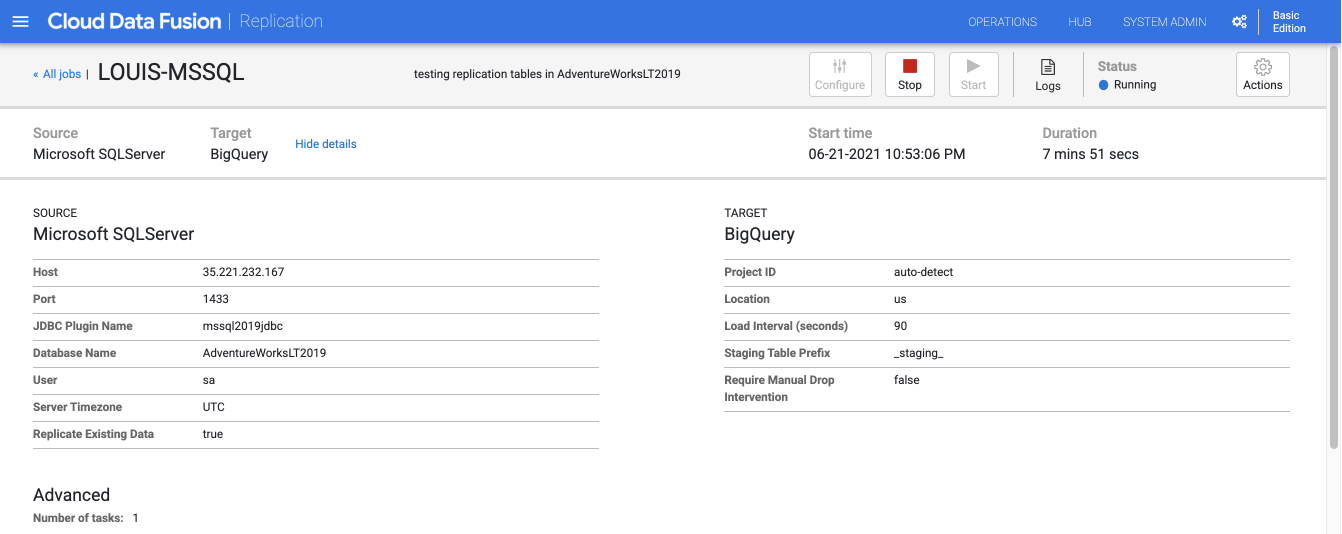
3. View the results in BigQuery
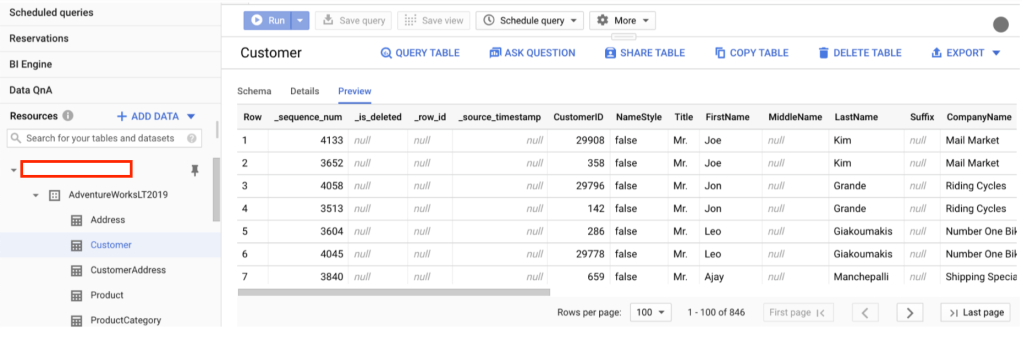
We can test by deleting some records in MSSQL and see if the deleted data will also be removed from BigQuery!
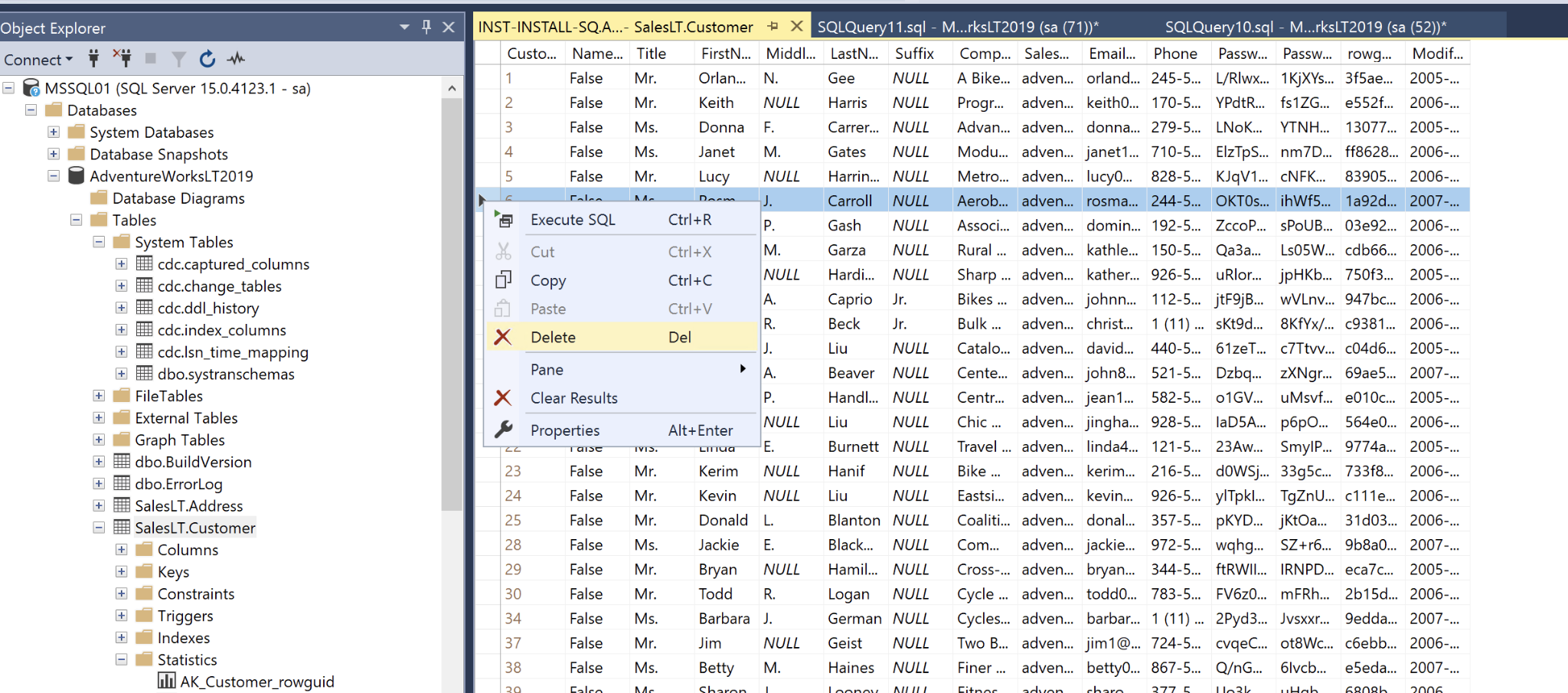
first is to delete one record in one table.
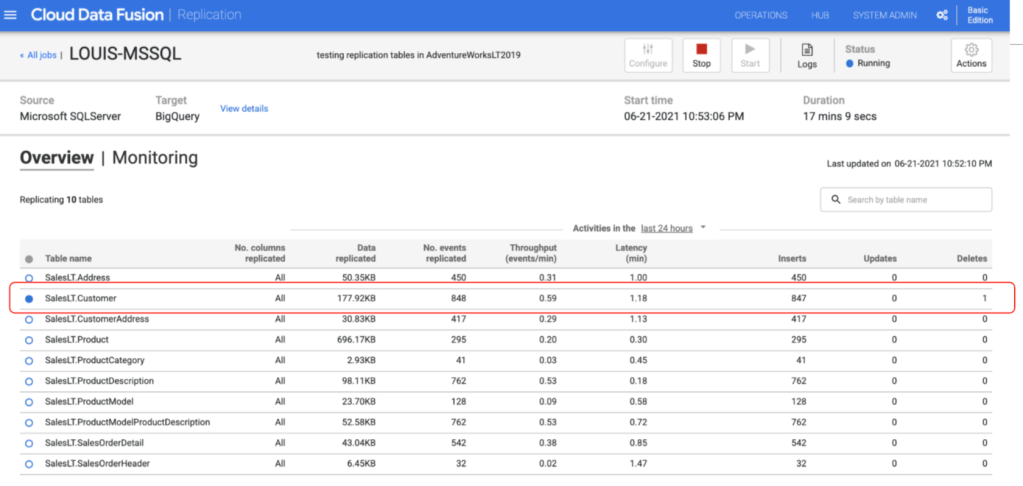
In CDF, showing that once there’s any record modified in the source, the data will be updated in the target side simultaneously leveraging CDF’s replication capability.
- Cloud SQL configuration tips
If you are connecting to Google Cloud SQL as the source through CDF with public IP, you need to take several additional configuraiotn steps for this task:
CDF has two main configuration setup time in mind:
Design time is when you are creating the replication pipeline in the CDF tenant project GUIs (similar to creating normal pipelines).
Runtime is when you actually run the replication, which is done on a Dataproc instance in the customer project (not in the tenant project). You’ll see the Dataproc instances automatically created in your project.
For the design time (initially creating the replication pipeline), your Cloud SQL instance will need 0.0.0.0/0 authorized network so that the CDF tenant project resources can access the Cloud SQL instance.
For the run time (after creating the pipeline, when you need to actually run the replication pipeline), you can remove the 0.0.0.0/0 at that point.
You can see several different connection discussion covered here:
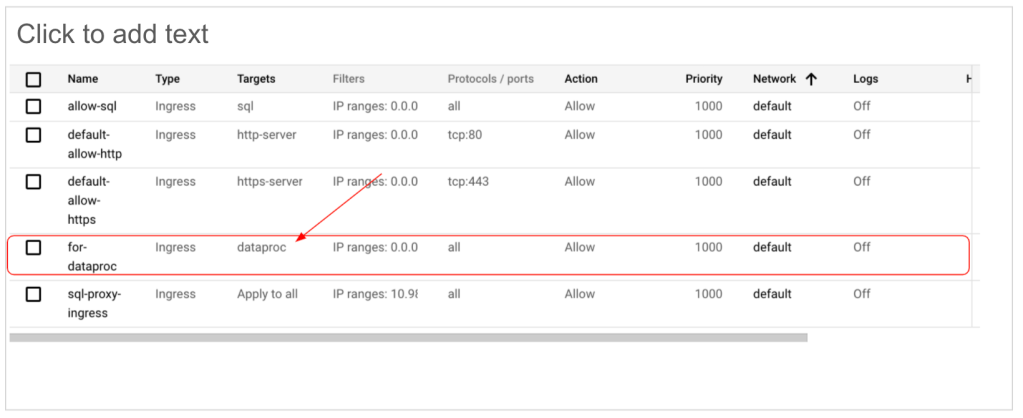
You can also consider to tag the Dataproc network for firewall rules, which make you easier to create related firewall rule in your VPC.
In replication job, click “Configure” to set the ‘Network Tags’ in Dataproc profile.
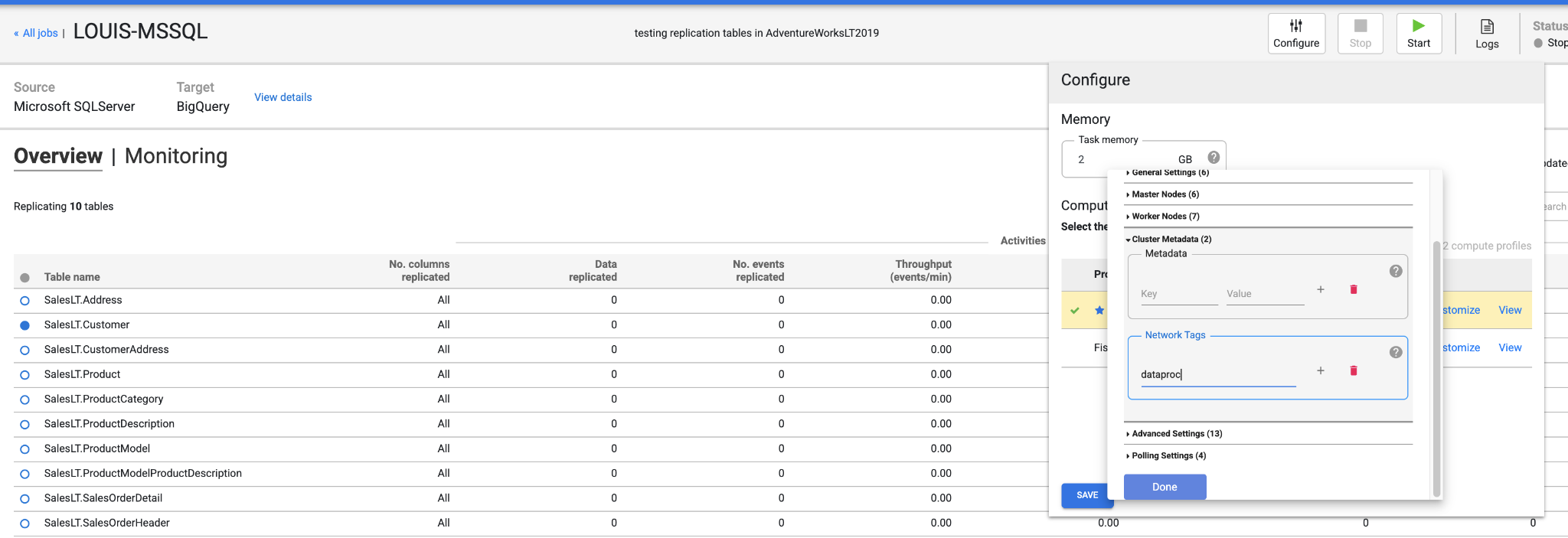
Add relevant firewall rules in your VPC:
To be no surprise, you may want to check the CDF pricing structure, it includes GCE, CDF, Dataproc, etc., you’d better check with Google sales for the detail of the overall pricing components involved in this pipeline. I hope this blog bring you a little help if you are planning to use Cloud Data Fusion for your database pipeline synchronization with BigQuery, thanks!
